- Análises›
- Amazon EMR›
- Recursos
Recursos do Amazon EMR
Fácil de usar
Visão geral
O Amazon EMR simplifica a criação e operação de ambientes de big data e aplicações. Os atributos do EMR relacionados incluem fácil provisionamento, escalabilidade gerenciada e reconfiguração de clusters, além do EMR Studio para desenvolvimento colaborativo.
Provisione clusters em minutos
É possível iniciar um cluster EMR em minutos. Você não precisa se preocupar com o provisionamento de infraestrutura, a configuração ou os ajustes de cluster. O EMR cuida dessas tarefas para que você concentre sua equipe no desenvolvimento de aplicativos de big data diferenciados.
Dimensione facilmente os recursos para atender às necessidades comerciais
É possível aumentar e reduzir a escala horizontalmente facilmente em políticas e deixar o cluster do EMR gerenciar automaticamente os recursos computacionais para atender às suas necessidades de uso e performance. Isso melhora a utilização do cluster e economiza custos.
EMR Studio
É um ambiente de desenvolvimento integrado (IDE) que torna fácil para os cientistas e engenheiros de dados desenvolverem, visualizarem e depurarem aplicações de engenharia de dados e ciência de dados programados em R, Python, Scala e PySpark. O EMR Studio oferece Notebooks Jupyter totalmente gerenciados e ferramentas como Spark UI e YARN Timeline Service para simplificar a depuração.
Alta disponibilidade com um único clique
Você pode facilmente configurar aplicações com vários mestres, como o YARN, o HDFS, o Apache Spark, o Apache HBase e o Apache Hive por meio de um único clique. Ao habilitar o suporte a vários mestres no EMR, o EMR configurará esses aplicativos para a alta disponibilidade e, no caso de falhas, fará failover automaticamente para um mestre em espera para que o cluster não seja interrompido, e colocará seus nós mestres em prateleiras distintas para reduzir o risco de falhas simultâneas. Os hosts são monitorados para detectar falhas e, quando problemas são detectados, novos hosts são provisionados e adicionados ao cluster automaticamente.
Ajuste de Escala Gerenciado do EMR
Redefine automaticamente o tamanho do seu cluster para melhor desempenho no menor custo possível. Com o EMR Managed Scaling, você especifica os limites mínimo e máximo de cálculo para seus clusters e o Amazon EMR automaticamente os adapta para melhor desempenho e utilização de recursos. O EMR Managed Scaling amostra continuamente as principais métricas associadas às cargas de trabalho em execução nos clusters.
Reconfigure facilmente os clusters em execução
Agora, você pode modificar a configuração de aplicativos executados em clusters do EMR, incluindo Apache Hadoop, Apache Spark, Apache Hive e Hue, sem reiniciar o cluster. A reconfiguração de aplicativos do EMR permite modificar aplicativos em execução, sem necessidade de desativar ou recriar o cluster. O Amazon EMR aplica as novas configurações e reinicia o aplicativo reconfigurado de forma controlada. As configurações podem ser aplicadas usando o console, o SDK ou a CLI.
Elástico
Visão geral
O Amazon EMR permite que você provisione de modo rápido e fácil a quantidade de capacidade necessária, além de adicionar e remover capacidade de forma automática ou manual. Isso é muito útil se você tiver requisitos de processamento variáveis e imprevisíveis. Por exemplo, se o maior volume de processamento ocorrer à noite, talvez você precise de 100 instâncias durante o dia e 500 instâncias à noite. Mas, por outro lado, você pode precisar de uma quantidade significativa de capacidade por um período curto de tempo. Com o Amazon EMR, você pode provisionar rapidamente centenas ou milhares de instâncias, escalar automaticamente para atender a requisitos de computação e encerrar o cluster quando o trabalho for concluído (para evitar pagar por capacidade ociosa).

Há duas opções principais para adicionar e remover capacidade:
Implemente vários clusters
Se você precisa de mais capacidade, pode executar rapidamente um cluster e encerrá-lo quando não precisar mais. Não há limite para quantos clusters você pode ter. Você pode querer usar vários clusters se tiver vários usuários e aplicativos. Por exemplo, você pode armazenar seus dados de entrada no Amazon S3 e executar um cluster para cada aplicativo que precisa para processar dados. Um cluster pode ser otimizado para CPU, um segundo cluster pode ser otimizado para armazenamento, etc.
Redimensione manualmente um cluster em execução
Com o Amazon EMR, é fácil usar o Ajuste de Escala Gerenciado do EMR, escalar automaticamente ou redefinir manualmente um cluster em execução. Aumente a escala horizontal de um cluster para aumentar temporariamente seu poder de processamento ou reduza a escala horizontal do cluster para economizar custos quando a capacidade estiver ociosa. Por exemplo, alguns clientes adicionam centenas de instâncias aos seus clusters quando ocorre seu processamento em lote, e removem as instâncias extras quando o processamento termina. Agora, ao adicionar instâncias ao cluster, o EMR poderá começar a utilizar capacidade provisionada assim que estiver disponível. Ao reduzir a escala, o EMR escolherá proativamente nós ociosos para reduzir o impacto sobre os trabalhos em execução.
Baixo custo
Visão geral
O Amazon EMR foi desenvolvido para reduzir o custo do processamento de grandes quantidades de dados. Alguns recursos que mantêm o baixo custo incluem baixa definição de preço por segundo, integração com instâncias spot do Amazon EC2, integração com as instâncias reservadas do Amazon EC2, elasticidade e integração com o Amazon S3.
Preços baixos por segundo
Os preços do Amazon EMR são definidos por segundo de instância, com um mínimo de um minuto, e começam em USD 0,015 por hora por instância para uma instância pequena (USD 131,40 por ano). Veja a seção de definição de preço para obter mais detalhes.
Integração Spot do Amazon EC2
O preço das instâncias spot do Amazon EC2 oscila com base na oferta e na demanda das instâncias, mas você nunca pagará mais que o preço máximo que especificou. O Amazon EMR facilita o uso de instâncias spot para que você economize tempo e dinheiro. Os clusters Amazon EMR incluem “nós de núcleo” que executam HDFS e “nós de tarefa” que não executam. Os nós de tarefa são ideais para spot, pois se o preço spot aumentar e você perder aquelas instâncias, você não perderá os dados armazenados no HDFS. (Saiba mais sobre os nós de núcleo e de tarefa). Com a combinação das frotas de instância, as estratégias de alocação para instâncias spot, o Ajuste de Escala Gerenciado do EMR e mais opções de diversificação, você agora pode otimizar o EMR para resiliência e custos. Para saber mais, leia o nosso blog.
Integração com o Amazon S3
O Sistema de Arquivos do EMR (EMRFS) permite que os clusters do EMR usem o Amazon S3 com eficiência e segurança como um depósito de objetos para o Hadoop. Você pode armazenar seus dados no Amazon S3 e usar vários clusters do Amazon EMR para processar o mesmo conjunto de dados. Cada cluster pode ser otimizado para uma determinada carga de trabalho, que pode ser mais eficiente que um único cluster atendendo a várias cargas de trabalho com requisitos diferentes. Por exemplo, você pode ter um cluster que é otimizado para E/S e outro, otimizado para CPU, cada um processando o mesmo conjunto de dados no Amazon S3. Além disso, armazenando seus dados de entrada e saída no Amazon S3, você pode encerrar clusters quando não forem mais necessários.
O EMRFS oferece uma ótima performance na leitura/gravação de/para o Amazon S3, é compatível com a criptografia do lado do servidor e com a criptografia do lado do cliente do S3 usando o AWS Key Management Service (KMS) ou chaves gerenciadas pelo cliente. Além disso, oferece uma visualização consistente opcional que verifica a consistência da listagem e da leitura após gravação para os objetos rastreados em seus metadados. Além disso, os clusters do Amazon EMR podem usar EMRFS e HDFS para que você não tenha que escolher entre o armazenamento no cluster e o Amazon S3.
Integração do Catálogo de Dados do AWS Glue
É possível usar o Catálogo de Dados do AWS Glue como um repositório gerenciado de metadados para armazenar metadados de tabela externa do Apache Spark e do Apache Hive. Além disso, ele disponibiliza uma descoberta automática de esquemas, bem como um histórico de versões de esquema. Isso permite persistir metadados de modo fácil para tabelas externas no Amazon S3, fora do cluster.
Datastores flexíveis
Visão geral
Com o Amazon EMR, você pode aproveitar vários armazéns de dados, incluindo o Amazon S3, o Hadoop Distributed File System (HDFS) e o Amazon DynamoDB.
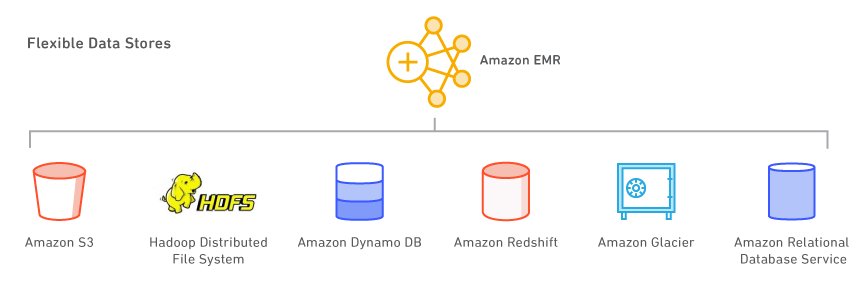
Amazon S3
O Amazon S3 é um serviço de armazenamento resiliente, escalável, seguro, rápido e econômico. Com o Sistema de Arquivos do EMR (EMRFS), o Amazon EMR pode usar o Amazon S3 com eficiência e segurança como um depósito de objetos para o Hadoop. O Amazon EMR fez inúmeras melhorias no Hadoop para que você possa processar grandes quantidades de dados armazenados no Amazon S3. Além disso, o EMRFS pode habilitar a visualização consistente para verificar a consistência de lista e de leitura após gravação para objetos no Amazon S3. O EMRFS oferece suporte à criptografia do lado do servidor e a criptografia do lado do cliente do S3 para processar objetos criptografados do Amazon S3. Você também pode usar o AWS Key Management Service (KMS) ou um fornecedor de chaves personalizadas.
Quando você executa seu cluster, o Amazon EMR transmite os dados do Amazon S3 para cada instâncias do seu cluster e começa a processá-lo imediatamente. Uma vantagem de armazenar seus dados no Amazon S3 e processá-lo com o Amazon EMR é que você pode usar vários clusters para processar os mesmos dados. Por exemplo, você pode ter um cluster de desenvolvimento Hive otimizado para memória e um cluster de desenvolvimento Pig otimizado para CPU, ambos usando o mesmo conjunto de dados de entrada.
Sistema de Arquivos Distribuído do Hadoop (HDFS)
O HDFS é o sistema de arquivos do Hadoop. A topologia atual do Amazon EMR agrupa suas instâncias em 3 grupos lógicos de instâncias: grupo mestre, que executa o YARN Resource Manager e o serviço HDFS Name Node; grupo principal, que executa o HDFS DataNode Daemon e o serviço YARN Node Manager, e grupo de tarefas, que executa o serviço YARN Node Manager. O Amazon EMR instala o HDFS no armazenamento associado às instâncias do grupo principal.
Cada instância do EC2 é fornecida com uma quantidade fixa de armazenamento, denominada “armazenamento de instâncias”, anexada à instância. Também é possível personalizar o armazenamento em uma instância adicionando volumes do Amazon EBS à instância. O Amazon EMR permite adicionar os tipos de volume de uso geral (SSD), provisionado (SSD) e magnético. Os volumes do EBS adicionados a um cluster do EMR não persistem dados após o encerramento do cluster. O EMR limpa automaticamente os volumes após o encerramento do cluster.
Também é possível habilitar a criptografia completa do HDFS usando uma configuração de segurança do Amazon EMR ou criar manualmente zonas de criptografia do HDFS com o Hadoop Key Management Server. Você pode usar uma opção de configuração de segurança para criptografar o dispositivo raiz EBS e armazenar volumes quando especificar o AWS KMS como seu principal provedor. Para mais informações, consulte Criptografia local de disco.
Amazon DynamoDB
O Amazon DynamoDB é um serviço de banco de dados NoSQL rápido e totalmente gerenciado. O Amazon EMR tem uma integração direta com o Amazon DynamoDB, assim você pode, com rapidez e eficiência, processar dados armazenados no Amazon DynamoDB e transferir dados entre o Amazon DynamoDB, o Amazon S3 e o HDFS no Amazon EMR.
Outros armazenamentos de dados da AWS
Você também pode usar o Amazon Relational Database Service (um serviço da Web que facilita a configuração, a operação e a escalabilidade de um banco de dados relacional na nuvem), o Amazon Glacier (um serviço de armazenamento de custo extremamente baixo que fornece armazenamento seguro e durável para arquivamento e backup de dados) e o Amazon Redshift (um serviço de data warehouse rápido, totalmente gerenciado e em escala de petabytes). O AWS Data Pipeline é um serviço da Web que ajuda os clientes a processar e movimentar dados de forma confiável entre diferentes serviços de armazenamento e computação da AWS (incluindo o Amazon EMR), além de fontes de dados on-premises, em intervalos especificados.
Use seus aplicativos de código aberto preferidos
Visão geral
Com os lançamentos com controle de versão no Amazon EMR, você pode facilmente selecionar e usar os projetos de código aberto mais recentes no cluster do EMR, como aplicativos nos ecossistemas do Apache Spark e Hadoop. O software é instalado e configurado pelo Amazon EMR para que você possa passar mais tempo agregando valor aos seus dados sem se preocupar com tarefas administrativas e relacionadas à infraestrutura.

Ferramentas para big data
Visão geral
O Amazon EMR é compatível com ferramentas poderosas e comprovadas do Hadoop, como o Apache Spark, o Apache Hive, o Presto e o Apache HBase. Cientistas de dados utilizam o EMR para executar ferramentas de aprendizagem profunda e machine learning, como o TensorFlow, o Apache MXNet, e usando ações de bootstrap, adicionam ferramentas e bibliotecas específicas de casos de uso. Analistas de dados usam o EMR Studio, Hue e os Notebooks EMR para o desenvolvimento interativo, para autorizar tarefas do Apache Spark e para enviar consultas SQL para o Apache Hive e o Presto. Engenheiros de dados usam o EMR para o desenvolvimento de data pipeline e o processamento de dados, e o Apache Hudi para simplificar o gerenciamento de dados incrementais e os casos de uso de privacidade de dados que exigem operações de inclusão, atualização e exclusão no nível de registro.

Processamento de dados e Machine Learning
O Apache Spark é um mecanismo no ecossistema do Hadoop que processa rapidamente grandes conjuntos de dados. Ele usa conjuntos de dados distribuídos resilientes (RDDs) na memória e tolerante a falhas, e gráficos direcionados acíclicos (DAGs) para definir transformações de dados. O Spark também inclui Spark SQL, Spark Streaming, MLlib e GraphX. Conheça o Spark e saiba mais sobre o Spark no EMR.
O Apache Flink é um mecanismo de fluxo de dados de streaming que facilita a execução do processamento de streams em tempo real em fontes de dados com alta throughput. Ele é compatível com semântica de tempo otimizada para eventos com falha, semântica do tipo exactly-once (exatamente uma vez), controle de pressão de retorno e APIs para escrever aplicativos de streaming e em lote. Conheça o Flink e saiba mais sobre o Flink no EMR.
O TensorFlow é uma biblioteca de matemática simbólica de código aberto para aplicações de inteligência de artificial e aprendizado profundo. O TensorFlow reúne vários modelos e algoritmos de machine learning e aprendizagem profunda, além de treinar e executar redes neurais profundas para muitos casos de uso diferentes. Saiba mais sobre o TensorFlow no EMR.
Gerenciamento de dados no Amazon S3 no nível de registro
O Apache Hudi é uma estrutura de gerenciamento de dados de código aberto usada para simplificar o processamento incremental de dados e o desenvolvimento de pipelines de dados. O Apache Hudi lhe permite gerenciar dados de registro no Amazon S3 para simplificar o Change Data Capture (CDC) e o streaming de consumo de dados, além de fornecer uma estrutura para lidar com casos de uso de privacidade de dados exigindo atualizações e exclusões no nível de registro. Saiba mais sobre o Apache Hudi no Amazon EMR.
SQL
O Apache Hive é um data warehouse e um pacote analítico de código aberto que é executado com base no Hadoop. O Hive é operado pela Hive QL, uma linguagem baseada em SQL, que permite aos usuários estruturar, resumir e consultar dados. O Hive QL vai além do SQL padrão, adicionando suporte de primeira classe às funções mapear/reduzir e a tipos de dados complexos e extensíveis definidos pelo usuário, como JSON e Thrift. Esse recurso permite o processamento de fontes de dados complexas e até não estruturadas, como documentos de texto e arquivos de log. O Hive permite extensões de usuário via funções definidas pelo usuário escritas em Java. O Amazon EMR tem feito inúmeras melhorias ao Hive, incluindo a integração direta com o Amazon DynamoDB e o Amazon S3. Por exemplo, com o Amazon EMR, você pode carregar partições de tabela automaticamente do Amazon S3, gravar dados em tabelas no Amazon S3 sem usar arquivos temporários e pode acessar recursos no Amazon S3, como roteiros para operações personalizadas de mapeamento/redução e bibliotecas adicionais. Conheça o Hive e saiba mais sobre o Hive no EMR.
O Presto é um mecanismo de consulta SQL distribuído de código aberto otimizado para baixa latência e análise de dados ad-hoc. Ele aceita o padrão ANSI SQL, que inclui consultas complexas, agregações, junções e funções de janela. O Presto pode processar dados de várias fontes, como o Hadoop Distributed File System (HDFS) e o Amazon S3. Conheça o Presto e saiba mais sobre o Presto no EMR.
O Apache Phoenix permite o uso de SQL de baixa latência com recursos de transação ACID em dados armazenados no Apache HBase. É possível criar facilmente índices secundários para obter performance adicional, como também visualizações diferentes sobre a mesma tabela subjacente do HBase. Saiba mais sobre o Phoenix no EMR.
NoSQL
O Apache HBase é um banco de dados de código aberto, não relacional e distribuído, modelado de acordo com o BigTable da Google. Foi desenvolvido como parte do projeto Hadoop da Apache Software Foundation e é executado com base no Hadoop Distributed File System (HDFS) para fornecer recursos similares aos da BigTable para Hadoop. O HBase disponibiliza uma maneira eficiente e tolerante a falhas de armazenar grandes quantidades de dados esparsos usando compactação e armazenamento baseado em colunas. Além disso, o HBase disponibiliza pesquisa rápida de dados porque armazena em cache dados de memória. O HBase é otimizado para operações de gravação sequencial, e é altamente eficiente para inserções, atualizações e exclusões em lote. O HBase funciona sem dificuldade com o Hadoop, compartilhando seu sistema de arquivos e servindo como entrada e saída direta para os trabalhos do Hadoop. O HBase também se integra ao Apache Hive, possibilitando consultas tipo SQL em tabelas HBase, junções com tabelas baseadas no Hive e suporte para Java Database Connectivity (JDBC). Com o EMR, você pode usar o S3 como um datastore do HBase, o que permite diminuir custos e reduzir complexidade operacional. Se você usa o HDFS como um datastore, é possível fazer backup do HBase no S3, além de restaurar usando um backup criado anteriormente. Conheça o HBase e saiba mais sobre o HBase no EMR.
Análise interativa
O EMR Studio é um ambiente de desenvolvimento integrado (IDE) que torna fácil para os cientistas e engenheiros de dados desenvolverem, visualizarem e depurarem aplicações de engenharia de dados e ciência de dados programados em R, Python, Scala e PySpark. O EMR Studio oferece Notebooks Jupyter totalmente gerenciados e ferramentas como Spark UI e YARN Timeline Service para simplificar a depuração.
O Hue é uma interface de usuário de código aberto para o Hadoop que facilita a execução e o desenvolvimento de consultas do Hive, o gerenciamento de arquivos no HDFS, a execução e o desenvolvimento de scripts Pig e o gerenciamento de tabelas. O Hue no EMR também se integra ao Amazon S3, permitindo executar consultas diretas no S3 e facilitando a transferência de arquivos entre o HDFS e o Amazon S3. Saiba mais sobre o Hue e o EMR.
O caderno Jupyter é uma aplicação Web de código aberto que você pode usar para criar e compartilhar documentos que contenham código ativo, equações, visualizações e texto narrativo. O JupyterHub permite hospedar várias instâncias de um servidor de Notebook Jupyter de usuário único. Ao criar um cluster do EMR com o JupyterHub, o EMR cria um contêiner do Docker em um nó principal do cluster. O JupyterHub, todos os componentes necessários do Jupyter e o Sparkmagic são executados no contêiner.
O Apache Zeppelin é uma GUI de código aberto que cria cadernos interativos e de colaboração para a exploração de dados usando o Spark. Você pode usar Scala, Python, SQL (usando Spark SQL) ou HiveQL para manipular dados e visualizar rapidamente resultados. Os blocos de anotações do Zeppelin podem ser compartilhados entre vários usuários, e as visualizações podem ser publicadas em painéis externos. Saiba mais sobre o Zeppelin no EMR.
Programação e fluxo de trabalho
O Apache Oozie é um programador de fluxo de trabalho do Hadoop, no qual você pode criar gráficos acíclicos dirigidos (DAGs) de ações. Você também pode acionar facilmente os fluxos de trabalho do Hadoop por atividades ou horário. Saiba mais sobre o Oozie no EMR. O AWS Step Functions permite a adição de automação de fluxos de trabalho resilientes a seus aplicativos. As etapas do seu fluxo de trabalho podem existir em qualquer lugar, incluindo nas funções do AWS Lambda, no Amazon Elastic Compute Cloud (EC2) ou no local. Saiba mais sobre o AWS Step Functions no EMR.
Outros projetos e ferramentas
O EMR também é compatível com uma variedade de outros aplicativos e ferramentas populares, como o R, o Apache Pig (processamento de dados e ETL), o Apache Tez (execução complexa do DAG), o Apache MXNet (aprendizagem profunda), o Ganglia (monitoramento), o Apache Sqoop (conector de banco de dados relacional), o HCatalog (gerenciamento de tabelas e armazenamento) e muito mais. A equipe do Amazon EMR mantém um repositório de ações de bootstrap de código aberto que pode ser usado para instalar software adicional, configurar clusters ou servir como exemplos de codificação de suas próprias ações de bootstrap.
Controle de acesso a dados
Visão geral
Por padrão, os processos de aplicações do Amazon EMR usam o perfil de instância do EC2 quando chamam outros serviços da AWS. Para clusters multilocatários, o Amazon EMR oferece três opções para gerenciar o acesso do usuário a dados do Amazon S3.
A integração com o AWS Lake Formation permite que você defina e gerencie políticas de autorização refinadas no AWS Lake Formation para acessar bancos de dados, tabelas e colunas no Catálogo de Dados do AWS Glue. Você pode aplicar as políticas de autorização em trabalhos enviados por meio dos Cadernos do Amazon EMR e do Apache Zeppelin para workloads interativas do EMR Spark, além de enviar eventos de auditoria ao AWS CloudTrail. Ao habilitar essa integração, você também habilita o Single Sign-On federado em blocos de anotações do EMR ou Apache Zeppelin a partir de sistemas de identidade corporativos compatíveis com Security Assertion Markup Language (SAML) 2.0.
A integração nativa com o Apache Ranger permite configurar um servidor Apache Ranger novo ou existente para definir e gerenciar políticas de autorização refinadas para usuários acessarem bancos de dados, tabelas e colunas de dados do Amazon S3 por meio do Hive Metastore. O Apache Ranger é uma ferramenta de código aberto utilizada para habilitar, monitorar e gerenciar a segurança abrangente de dados em toda a plataforma Hadoop.
Essa integração nativa permite definir três tipos de políticas de autorização no servidor Policy Admin do Apache Ranger. Você pode definir autorização de nível de tabela, coluna e linha para o Hive, autorização de nível de tabela e coluna para o Spark e autorização de nível de prefixo objeto para o Amazon S3. O Amazon EMR instala e configura automaticamente os plug-ins do Apache Ranger correspondentes no cluster. Esses plug-ins do Ranger são sincronizados com o servidor Policy Admin para políticas de autorização, aplicação do controle de acesso a dados e envio de eventos de auditoria para o Amazon CloudWatch Logs.
O Mapeador de Perfis de Usuário do Amazon EMR permite utilizar as permissões do AWS IAM para gerenciar os acessos aos recursos da AWS. Você pode criar mapeamentos entre os usuários (ou grupos) e funções do IAM personalizadas. Um usuário ou grupo só pode acessar os dados permitidos pela função do IAM personalizada. No momento, esse recurso só está disponível por meio dos AWS Labs.
Experiência híbrida consistente
Visão geral
O AWS Outposts é um serviço gerenciado que leva a infraestrutura, os serviços, as APIs e as ferramentas da AWS a praticamente qualquer data center, espaço de colocalização ou instalação on-premises para oferecer uma experiência híbrida verdadeiramente consistente. O Amazon EMR no AWS Outposts permite que você implante e gerencie clusters do EMR no data center usando o mesmo Console de Gerenciamento da AWS, kit de desenvolvimento de software (SDK) e interface de linha de comandos (CLI) usados para o EMR.
Recursos adicionais
Selecione a instância adequada para seu cluster
Você escolhe quais tipos de instâncias do EC2 provisionar no seu cluster (padrão, com mais memória, com CPU de alta performance, com E/S de alta performance etc.) de acordo com os requisitos das aplicações. Você tem acesso à raiz de cada instância e pode personalizar totalmente seu cluster para que se ajuste aos seus requisitos. Saiba mais sobre os tipos de instância compatíveis com o Amazon EC2. O Amazon EMR agora oferece até 30% menos custo e até 15% de melhoria no desempenho para cargas de trabalho Spark em instâncias baseadas no Graviton2 Saiba mais em nosso blog.
Controle o acesso da rede ao seu cluster
Você pode executar seu cluster em uma Amazon Virtual Private Cloud (VPC), uma seção logicamente isolada da Nuvem AWS. Você tem controle total sobre seu ambiente de redes virtuais, incluindo a seleção do seu próprio intervalo de endereços IP, a criação de sub-redes e a configuração de tabelas de rotas e gateways de rede. Saiba mais sobre o Amazon EMR e a Amazon VPC.
Depure suas aplicações
Quando você habilita a depuração em um cluster, o Amazon EMR guarda os arquivos de log no Amazon S3 e os indexa. Em seguida, você pode usar a interface gráfica no console para percorrer os logs e visualizar o histórico de trabalhos de forma intuitiva. Saiba mais sobre a depuração de trabalhos do Amazon EMR.
Gerencie usuários, permissões e criptografia
É possível usar ferramentas do AWS Identity and Access Management (AWS IAM), como os usuários e os perfis do IAM, para controlar o acesso e as permissões. Por exemplo, você pode conceder a determinados usuários acesso de leitura, mas não de gravação, aos seus clusters. Além disso, você pode usar as configurações de segurança do Amazon EMR para definir várias opções de criptografia de dados ociosos e em trânsito, incluindo o suporte à criptografia do Amazon S3 e à autenticação do Kerberos. Saiba mais sobre como controlar o acesso ao seu cluster e sobre as opções de criptografia do Amazon EMR.
Monitore o cluster
Você pode usar o Amazon CloudWatch para monitorar métricas personalizadas do Amazon EMR, como o número médio de tarefas de mapeamento e redução em execução. Você também pode definir os alarmes nessas métricas. Saiba mais sobre o monitoramento de clusters do Amazon EMR.
Instale um software adicional
Você pode recorrer a ações de bootstrap ou a uma imagem de máquina da Amazon (AMI) personalizada em execução no Amazon Linux para instalar um software adicional no seu cluster. As ações de bootstrap são roteiros que são executados nos nós do cluster quando o Amazon EMR executa o cluster. Elas são executadas antes que o Hadoop inicie e antes que o nó comece a processar dados. Também é possível pré-carregar e usar software em uma AMI personalizada do Amazon Linux. Saiba mais sobre as ações de bootstrap do Amazon EMR e as AMIs personalizadas do Amazon Linux.
Responda aos eventos
Você pode usar os tipos de evento do Amazon EMR no Amazon CloudWatch Events para responder às alterações de estado em seus clusters do Amazon EMR. Usando regras simples que você pode configurar rapidamente, combine eventos e encaminhe-os para tópicos do Amazon SNS, funções do AWS Lambda, filas do Amazon SQS, entre outros. Saiba mais sobre os eventos em clusters do Amazon EMR.
Copie dados com eficiência
É possível mover rapidamente grandes quantidades de dados do Amazon S3 para o HDFS, do HDFS para o Amazon S3 e entre buckets do Amazon S3 usando o S3DistCp do Amazon EMR, uma extensão da ferramenta de código aberto Distcp, que usa o MapReduce para mover com eficiência grandes quantidades de dados. Saiba mais sobre o S3DistCp.
Agende fluxos de trabalho recorrentes
Você pode usar o AWS Data Pipeline para programar fluxos de trabalho recorrentes envolvendo o Amazon EMR. O AWS Data Pipeline é um web service que ajuda você a processar e movimentar dados de forma confiável entre diferentes serviços de armazenamento e computação da AWS, inclusive fontes de dados locais, em intervalos especificados. Saiba mais sobre o Amazon EMR e o AWS Data Pipeline.
JAR personalizado
Grave um programa do Java, faça a compilação com a versão do Hadoop que pretende usar e faça upload no Amazon S3. Você pode, então, enviar trabalhos do Hadoop para o cluster usando a interface JobClient do Hadoop. Saiba mais sobre o processamento Custom JAR com o Amazon EMR.
Aprendizado profundo
Use frameworks conhecidos de aprendizado profundo como o Apache MXNet para definir, treinar e implantar redes neurais profundas. Você pode usar essas estruturas em clusters do Amazon EMR com instâncias de GPU. Saiba mais sobre o MXNet no Amazon EMR.