



데이터 모델링이란 무엇인가요?
데이터 모델링은 조직의 정보 수집과 관리 시스템을 정의하는 시각적 표현 또는 청사진을 생성하는 프로세스입니다. 이 청사진 또는 데이터 모델은 데이터 분석자, 과학자, 엔지니어와 같은 다양한 이해관계자들이 조직의 데이터에 대한 통일된 개념을 생성할 수 있게 돕습니다. 이 모델은 해당 비즈니스가 수집하는 데이터, 서로 다른 데이터 세트 사이의 관계, 데이터를 저장하고 분석하는 데 사용되는 방식을 설명합니다.
데이터 모델링이 중요한 이유는 무엇인가요?
오늘날 조직은 다양한 소스에서 많은 양의 데이터를 수집합니다. 그러나 원시 데이터로는 충분하지 않습니다. 수익성 있는 비즈니스 결정을 내리는 데 도움이 되는 실행 가능한 인사이트를 얻기 위해 데이터를 분석해야 합니다. 정확한 데이터 분석을 위해서는 효율적인 데이터 수집, 저장 및 처리가 필요합니다. 여러 데이터베이스 기술과 데이터 처리 도구가 있으며 데이터 세트마다 효율적인 분석을 위한 도구가 다릅니다.
데이터 모델링은 데이터를 이해하고 이 데이터를 저장 및 관리하기 위한 올바른 기술 선택을 할 수 있는 기회를 제공합니다. 건축가가 집을 짓기 전에 청사진을 설계하는 것과 같은 방식으로, 비즈니스 이해관계자는 조직을 위한 데이터베이스 솔루션을 엔지니어링하기 전에 데이터 모델을 설계합니다.
데이터 모델링은 다음과 같은 이점을 제공합니다.
- 데이터베이스 소프트웨어 개발 오류 감소
- 데이터베이스 설계 및 생성 속도와 효율성 촉진
- 조직 전체에서 데이터 문서화 및 시스템 설계의 일관성 조성
- 데이터 엔지니어와 비즈니스 인텔리전스 팀 간의 커뮤니케이션 촉진
데이터 모델 유형에는 무엇이 있나요?
데이터 모델링은 일반적으로 데이터를 개념적으로 표현한 다음 선택한 기술의 맥락에서 다시 표현하는 것으로 시작됩니다. 분석가와 이해관계자는 데이터 설계 단계에서 여러 유형의 데이터 모델을 만듭니다. 다음은 데이터 모델의 주요 세 가지 유형입니다.
개념적 데이터 모델
개념적 데이터 모델은 데이터에 대한 큰 그림 보기를 제공합니다. 즉, 다음을 설명합니다.
- 시스템에 들어 있는 데이터
- 데이터 속성 및 데이터에 대한 조건 또는 제약 조건
- 데이터와 관련된 비즈니스 규칙
- 최고의 데이터 구성 방법
- 보안 및 데이터 무결성 요구 사항
비즈니스 이해관계자와 분석가는 일반적으로 개념적 모델을 만듭니다. 이는 공식 데이터 모델링 규칙을 따르지 않는 간단한 다이어그램 표현입니다. 중요한 점은 기술 및 비기술 이해관계자가 공통의 비전을 공유하고 데이터 프로젝트의 목적, 범위 및 설계에 대해 의견 일치를 보는 데 개념적 모델이 도움이 된다는 것입니다.
개념적 데이터 모델의 예
예를 들어 자동차 대리점에 대한 개념적 데이터 모델은 다음과 같은 데이터 엔터티를 표시할 수 있습니다.
- 대리점이 갖고 있는 다양한 매장에 대한 정보를 나타내는 Showrooms 엔터티
- 대리점이 현재 보유하고 있는 여러 대의 자동차를 나타내는 Cars 엔터티
- 대리점에서 자동차를 구매한 모든 고객을 나타내는 Customers 엔터티
- 실제 판매에 대한 정보를 나타내는 Sales 엔터티
- 대리점에서 일하는 모든 판매원에 대한 정보를 나타내는 Salesperson 엔터티
이 개념적 모델에는 다음과 같은 비즈니스 요구 사항도 포함됩니다.
- 모든 자동차는 특정 쇼룸 소속이어야 합니다.
- 모든 판매에는 최소 한 명의 판매원과 한 명의 고객이 연결되어 있어야 합니다.
- 모든 자동차에는 브랜드 이름과 제품 번호가 있어야 합니다.
- 모든 고객은 전화번호와 이메일 주소를 제공해야 합니다.
따라서 개념적 모델은 비즈니스 규칙과 기본 물리적 데이터베이스 관리 시스템(DBMS) 간의 다리 역할을 합니다. 개념적 데이터 모델을 도메인 모델이라고도 합니다.
논리적 데이터 모델
논리적 데이터 모델은 개념적 데이터 클래스를 기술적 데이터 구조에 매핑하며, 다음과 같이 개념적 데이터 모델에서 식별된 데이터 개념과 복잡한 데이터 관계에 대한 자세한 내용을 제공합니다.
- 다양한 속성의 데이터 유형(예: 문자열 또는 숫자)
- 데이터 엔터티 간의 관계
- 데이터의 기본 속성 또는 키 필드
데이터 아키텍트와 분석가는 협업을 통해 논리적 모델을 만듭니다. 이들은 표현을 생성하기 위해 여러 공식 데이터 모델링 시스템 중 하나를 따릅니다. 민첩한 팀은 이 단계를 건너뛰고 개념 모델에서 실제 모델로 바로 넘어가기도 합니다. 그러나 이러한 모델은 데이터 웨어하우스라는 대규모 데이터베이스와 자동 보고 시스템을 설계하는 데 유용합니다.
논리적 데이터 모델의 예
자동차 대리점 예에서 논리적 데이터 모델은 개념적 모델을 확장하고 다음과 같이 데이터 클래스를 더 심층적으로 살펴봅니다.
- Showrooms 엔터티에는 텍스트 데이터 형식의 이름 및 위치 필드와 숫자 데이터 형식의 전화번호 필드가 있습니다.
- Customers 엔터티에는 [email protected] 또는 [email protected] 형식의 이메일 주소 필드가 있습니다. 필드 이름은 100자 이하여야 합니다.
- Sales 엔터티에는 고객 이름 필드, 판매원 이름 필드, 날짜 데이터 형식의 판매 날짜 필드 및 10진수 데이터 형식의 금액 필드가 있습니다.
따라서 논리적 모델은 개념적 데이터 모델과 개발자가 데이터베이스를 만드는 데 사용하는 기본 기술 및 데이터베이스 언어 사이의 다리 역할을 합니다. 그러나 논리적 모델은 기술에 구애받지 않으며 모든 데이터베이스 언어로 구현할 수 있습니다. 데이터 엔지니어와 이해관계자는 일반적으로 논리적 데이터 모델을 만든 후 기술 결정을 내립니다.
물리적 데이터 모델
물리적 데이터 모델은 논리적 데이터 모델을 특정 DBMS 기술에 매핑하고 소프트웨어의 용어를 사용합니다. 예를 들어 다음에 대한 세부 정보를 제공합니다.
- DBMS에 표현된 데이터 필드 유형
- DBMS에 표현된 데이터 관계
- 성능 조정과 같은 추가 세부 정보
데이터 엔지니어는 최종 설계 구현 전에 물리적 모델을 만듭니다. 또한 공식 데이터 모델링 기술을 따라 설계의 모든 측면을 다뤘는지 확인합니다.
물리적 데이터 모델의 예
자동차 대리점이 Amazon S3 Glacier Flexible Retrieval에서 데이터 아카이브를 생성하기로 결정했다고 가정하겠습니다. 물리적 데이터 모델은 다음 사양을 설명합니다.
- Sales에서 판매 금액은 float 데이터 형식이고 판매 날짜는 타임스탬프 데이터 형식입니다.
- Customers에서 고객 이름은 문자열 데이터 형식입니다.
- S3 Glacier Flexible Retrieval 용어에서 볼트는 데이터의 지리적 위치입니다.
물리적 데이터 모델에는 볼트를 생성할 AWS 리전과 같은 추가 세부 정보도 포함됩니다. 따라서 물리적 데이터 모델은 논리적 데이터 모델과 최종 기술 구현 사이의 다리 역할을 합니다.
데이터 모델링 기술 유형에는 무엇이 있나요?
데이터 모델링 기술은 다양한 데이터 모델을 생성하는 데 사용할 수 있는 다양한 방법입니다. 접근 방식은 데이터베이스 개념과 데이터 거버넌스 혁신의 결과로 시간 경과에 따라 발전해 왔습니다. 데이터 모델링의 주요 유형은 다음과 같습니다.
계층적 데이터 모델링
계층적 데이터 모델링에서는 다양한 데이터 요소 간의 관계를 트리 형식으로 나타낼 수 있습니다. 계층적 데이터 모델은 상위 또는 루트 데이터 클래스가 여러 하위 항목에 매핑되는 일대다 관계를 나타냅니다.
자동차 대리점 예에서 상위 클래스인 Showrooms에 Cars 및 Salespeople 엔터티가 모두 하위 항목으로 포함됩니다. 한 쇼룸에 여러 대의 자동차와 판매원이 있기 때문입니다.
그래프 데이터 모델링
계층적 데이터 모델링은 시간 경과에 따라 그래프 데이터 모델링으로 발전했습니다. 그래프 데이터 모델은 엔터티를 동등하게 취급하는 데이터 관계를 나타냅니다. 엔터티는 상위 또는 하위 개념 없이 일대다 또는 다대다 관계로 서로 연결할 수 있습니다.
예를 들어, 한 쇼룸에 판매원이 여러 명 있을 수 있고, 위치에 따라 교대 근무 시간이 다를 경우 한 판매원이 여러 쇼룸에서 일할 수도 있습니다.
관계형 데이터 모델링
관계형 데이터 모델링은 데이터 클래스를 테이블로 시각화하는 널리 사용되는 모델링 접근 방식입니다. 실제 엔터티 관계를 나타내는 키를 사용하여 서로 다른 데이터 테이블을 결합하거나 연결합니다. 관계형 데이터베이스 기술을 사용하여 정형 데이터를 저장할 수 있으며 관계형 데이터 모델은 관계형 데이터베이스 구조를 나타내는 유용한 방법입니다.
예를 들어 자동차 대리점에 다음과 같이 Salespeople 테이블과 Cars 테이블을 나타내는 관계형 데이터 모델이 있습니다.
| Salesperson ID | Name |
| 1 | Jane |
| 2 | John |
| Car ID | Car Brand |
| C1 | XYZ |
| C2 | ABC |
Salesperson ID와 Car ID는 개별 실제 엔티티를 고유하게 식별하는 프라이머리 키입니다. 쇼룸 테이블에서 이러한 프라이머리 키는 데이터 세그먼트를 연결하는 외래 키 역할을 합니다.
| Showroom ID | Showroom name | Salesperson ID | Car ID |
| S1 | NY Showroom | 1 | C1 |
관계형 데이터베이스에서는 프라이머리 키와 외래 키가 함께 작동하여 데이터 관계를 표시합니다. 앞의 표는 쇼룸에 판매원과 자동차가 있을 수 있음을 보여줍니다.
엔터티-관계 데이터 모델링
엔터티-관계(ER) 데이터 모델링은 공식 다이어그램을 사용하여 데이터베이스의 엔터티 간 관계를 나타냅니다. 데이터 아키텍트는 여러 ER 모델링 도구를 사용하여 데이터를 나타냅니다.
객체 지향 데이터 모델링
객체 지향 프로그래밍은 객체라는 데이터 구조를 사용하여 데이터를 저장합니다. 이러한 데이터 객체는 실제 객체의 소프트웨어 추상화입니다. 예를 들어, 객체 지향 데이터 모델에서 자동차 대리점은 이름, 주소 및 전화 번호와 같은 속성을 가진 Customers와 같은 데이터 객체를 갖습니다. 모든 실제 고객이 고객 데이터 객체로 표현되도록 고객 데이터를 저장합니다.
객체 지향 데이터 모델은 관계형 데이터 모델의 많은 한계를 극복하고 멀티미디어 데이터베이스에서 널리 사용됩니다.
차원 데이터 모델링
최신 엔터프라이즈 컴퓨팅은 데이터 웨어하우스 기술을 사용하여 분석을 위해 대량의 데이터를 저장합니다. 데이터 웨어하우스에서 고속 데이터 저장 및 검색을 위해 차원 데이터 모델링 프로젝트를 사용할 수 있습니다. 차원 모델은 중복 데이터를 사용하며 데이터 저장에 더 적은 공간을 사용하는 것보다 성능을 우선시합니다.
예를 들어 차원 데이터 모델의 경우 자동차 대리점에 Car, Showroom 및 Time과 같은 차원이 있습니다. Car 차원에는 이름 및 브랜드와 같은 속성이 있지만 Showroom 차원에는 주, 도시, 거리 이름 및 쇼룸 이름과 같은 계층이 있습니다.
데이터 모델링 프로세스란 무엇인가요?
데이터 모델링 프로세스는 포괄적 데이터 모델을 만들 때까지 반복적으로 수행해야 하는 일련의 단계를 따릅니다. 모든 조직의 다양한 이해관계자가 모여 완전한 데이터 보기를 만듭니다. 단계는 데이터 모델링 유형에 따라 다르지만 일반적인 개요는 다음과 같습니다.
1단계: 엔터티 및 해당 속성 식별
데이터 모델의 모든 엔터티를 식별합니다. 각 엔터티는 다른 모든 엔터티와 논리적으로 구별되어야 하며 사람, 장소, 사물, 개념 또는 이벤트를 나타낼 수 있습니다. 각 엔터티는 하나 이상의 고유한 속성을 가지고 있기 때문에 고유합니다. 데이터 모델에서 엔터티는 명사에 해당하고 속성은 형용사에 해당합니다.
2단계: 엔터티 간의 관계 식별
서로 다른 엔터티 간의 관계가 데이터 모델링의 핵심입니다. 비즈니스 규칙은 처음에 개념적 수준에서 이러한 관계를 정의합니다. 데이터 모델에서 관계는 동사에 해당합니다. 예를 들어, 판매원이 많은 차를 판매하거나 쇼룸이 많은 판매원을 고용합니다.
3단계: 데이터 모델링 기법 식별
엔터티와 해당 관계를 개념적으로 이해한 후 사용 사례에 가장 적합한 데이터 모델링 기술을 결정할 수 있습니다. 예를 들어 정형 데이터에는 관계형 데이터 모델링을 사용하고 비정형 데이터에는 차원 데이터 모델링을 사용할 수 있습니다.
4단계: 최적화 및 반복
기술 및 성능 요구 사항에 맞게 데이터 모델을 더 최적화할 수 있습니다. 예를 들어 Amazon Aurora와 구조적 쿼리 언어(SQL)를 사용하려는 경우 엔터티를 테이블에 직접 넣고 외래 키를 사용하여 관계를 지정합니다. 반면에 Amazon DynamoDB를 사용하기로 선택한 경우 테이블을 모델링하기 전에 액세스 패턴에 대해 생각해야 합니다. DynamoDB는 속도를 우선시하므로 먼저 데이터에 액세스하는 방법을 결정한 다음 액세스할 형식으로 데이터를 모델링합니다.
시간 경과에 따라 기술과 요구 사항이 변경됨에 따라 일반적으로 이러한 단계를 반복적으로 재방문하게 됩니다.
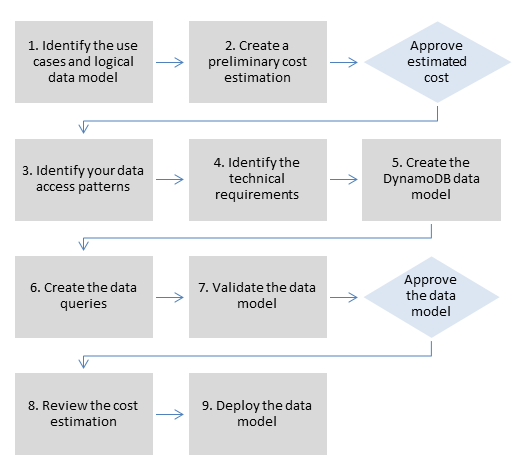
AWS는 데이터 모델링에 관해 어떤 도움을 줄 수 있나요?
또한 더 빠르고 쉬운 데이터 모델링을 위해 AWS Amplify DataStore를 사용하여 모바일 및 웹 애플리케이션을 구축할 수 있습니다. 관계로 데이터 모델을 정의하기 위한 시각적 및 코드 기반 인터페이스가 있어 애플리케이션 개발을 가속화할 수 있습니다.
지금 무료 계정을 만들어 AWS에서 데이터 모델링을 시작하세요.