Amazon EMR 기능
Amazon EMR을 사용하면 필요한 용량을 신속하고 손쉽게 프로비저닝할 수 있고 자동이나 수동으로 용량을 추가 및 제거할 수 있습니다. 따라서 처리 요구 사항이 일정하지 않거나 예측 불가능한 경우에 매우 유용합니다. 예를 들어, 야간에 대용량의 처리 작업이 발생할 경우 주간에 100개의 인스턴스가 필요하고 야간에 500개의 인스턴스가 필요할 수 있습니다. 또는 단기간 상당한 용량이 필요할 수도 있습니다. Amazon EMR을 사용하면 신속하게 수백 개 또는 수천 개의 인스턴스를 프로비저닝하고, 컴퓨팅 요구 사항에 맞춰 자동으로 확장하며, 유휴 용량에 대한 비용이 더 이상 청구되지 않도록 작업 완료 시 클러스터를 종료할 수 있습니다.

용량을 추가하거나 제거할 수 있는 두 가지 메인 옵션이 있습니다.
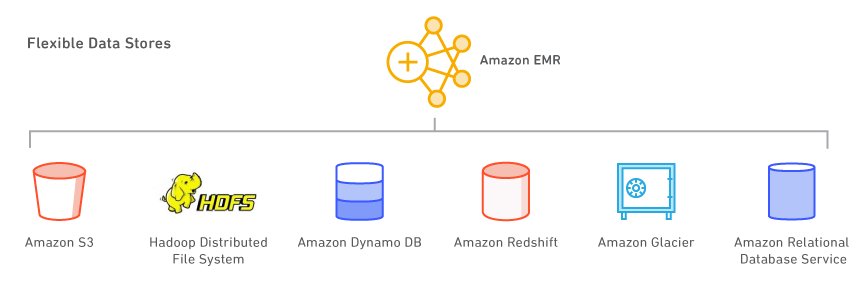
Amazon EMR을 사용하면 Amazon S3, 하둡 분산 파일 시스템(HDFS) 및 Amazon DynamoDB 등의 여러 데이터 스토어를 활용할 수 있습니다.
Amazon EMR의 버전이 지정된 릴리스에서는 Apache Spark 및 하둡 에코시스템의 애플리케이션을 비롯하여 EMR 클러스터의 최신 오픈 소스 프로젝트를 손쉽게 선택하여 사용할 수 있습니다. Amazon EMR에서 소프트웨어를 설치하고 구성하므로 사용자는 인프라와 관리 작업에 대한 걱정 없이 데이터 가치를 높이는 데 더 많은 시간을 투자할 수 있습니다.

Amazon EMR은 Apache Spark, Apache Hive, Presto 및 Apache HBase와 같은 강력하고 입증된 하둡 도구를 지원합니다. 데이터 사이언티스트는 EMR을 사용하여 TensorFlow, Apache MXNet와 같은 딥 러닝 및 기계 학습 도구를 실행하고 부트스트랩 작업을 사용하여 자체 사용 사례별 도구 및 라이브러리를 추가할 수 있습니다. 데이터 분석가는 EMR Studio, Hue 및 EMR Notebooks를 대화형 개발에 사용하여 Apache Spark 작업을 작성하고 Apache Hive 및 Presto에 SQL 쿼리를 제출할 수 있습니다. 데이터 엔지니어는 데이터 파이프라인 개발 및 데이터 처리에 EMR을 사용하고 Apache Hudi를 사용하여 레코드 수준 삽입, 업데이트 및 삭제 작업이 필요한 증분 데이터 관리 및 데이터 프라이버시 사용 사례를 간소화할 수 있습니다.
